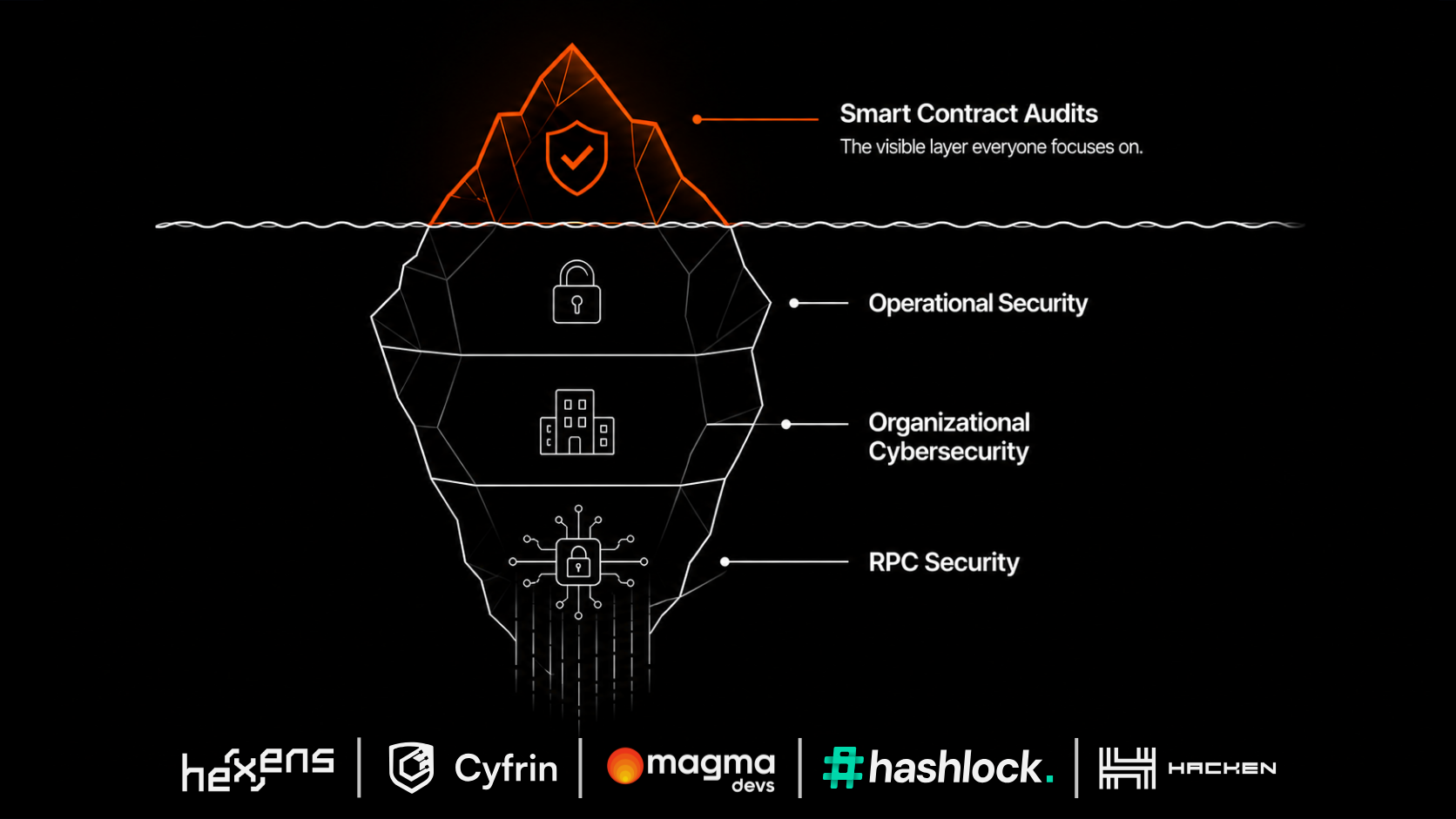
RPC is one of the most important infrastructure layers in a blockchain application. But in many companies, it is still treated like a basic vendor setting.
That creates a gap. The product may look mature. The company may serve serious customers. The application may handle valuable transactions. But underneath, the RPC setup may still depend on one provider, limited failover, weak observability, and unclear data validation.
That is not enterprise-ready.
If your product depends on blockchain data, your team should be able to answer the following 10 questions clearly.
1. Do we rely on one RPC provider per chain?
This is the first and most important question. If the answer is yes, you have a single point of failure. Even if the provider is strong, your application is still exposed to that provider's outages, latency, rate limits, and data issues.
Enterprise-grade infrastructure should not depend on one path to critical data.
2. Do we have automatic failover?
Manual failover is not enough. During an incident, every minute matters. If engineers need to wake up, investigate, change configuration, and redeploy, users may already be impacted.
Automatic failover allows the system to move traffic away from unhealthy providers faster. But automatic failover must also be controlled and observable. The team needs to know when it happened, why it happened, and what impact it had.
3. Do we measure latency by provider, chain, and method?
Average latency is not enough. A provider may perform well on one chain and poorly on another. It may be fast for one method and slow for another.
Enterprise teams should understand performance at a more granular level. Useful questions include:
- Which provider is fastest for each chain?
- Which provider is becoming slower over time?
- Are there specific RPC methods causing issues?
- Are users in certain regions affected more than others?
Without this visibility, routing decisions are mostly guesses.
4. Do we validate responses across providers?
Availability tells you whether a provider answered. Validation tells you whether the answer can be trusted.
For low-risk use cases, one response may be enough. For critical use cases, teams should consider comparing responses across providers and detecting disagreement. This is especially important for transaction status, balances, block data, and other sensitive flows.
5. Do we know when providers disagree?
Provider disagreement is a warning signal. It may mean one provider is stale, misconfigured, delayed, or experiencing an issue. If your system cannot detect disagreement, it may continue operating on bad assumptions.
Enterprise RPC infrastructure should make inconsistencies visible.
6. Do we have alerts before users are impacted?
Many teams learn about RPC issues from users, support tickets, or customer escalations. That is backwards. Your team should know before users know.
Strong monitoring should detect rising latency, error rates, provider disagreement, rate limits, and abnormal behavior early.
7. Do we have provider-level observability?
It is not enough to know that "RPC is having issues." You need to know which provider, which chain, which method, which region, and which application flow is affected.
Provider-level observability helps teams debug faster, hold vendors accountable, and make better architecture decisions. Without it, incident response becomes guesswork.
8. Can we route based on performance and reliability?
A static provider setup assumes the best provider is always the same. That is rarely true. Performance changes. Reliability changes. Provider behavior changes.
A stronger setup can route intelligently based on live or recent provider performance. This can improve latency, reduce incidents, and make better use of multiple providers.
9. Do we have protection against provider rate limits?
Rate limits often become painful during peak demand. That is exactly when your application needs infrastructure to work best.
If one provider throttles traffic, your system should be able to route around the issue, distribute load, or apply clear fallback rules. If your team only discovers rate-limit exposure during high-volume periods, the architecture is not ready.
10. Can we prove our RPC layer is enterprise-ready?
This is the board-level and customer-facing question. Can you show your customers, partners, auditors, or internal leadership that your RPC setup is resilient?
Can you prove redundancy, failover, monitoring, validation, incident response, provider visibility, and operational ownership?
Enterprise buyers do not only care that the system works today. They care that it is designed to keep working under stress.
How to score yourself
If you answered "no" or "not sure" to more than three questions, your RPC layer likely needs attention. If you answered "no" to provider redundancy, automatic failover, or response validation, the risk is more serious. Those are not small gaps. They are core infrastructure weaknesses.
Where Smart Router fits
Magma's Smart Router helps blockchain teams move from a basic RPC setup to an enterprise-grade RPC layer. It is designed to support multi-provider routing, automatic failover, performance-aware routing, response validation, provider-level observability, and reduced dependency on a single RPC vendor.
The goal is to help teams operate RPC like a critical infrastructure layer, not a hidden dependency.
The bottom line
RPC infrastructure deserves the same seriousness as any other production-critical system. If your application depends on blockchain data, your RPC layer should be redundant, observable, validated, and ready for incidents.
The worst time to discover an RPC weakness is during a live customer-impacting event.
How exposed is your RPC stack?
Take the 2-minute Secure RPC Assessment and get a personalized risk report.
Run the assessment